Summary and findings¶
Following are some of the outcomes of the data reconciliation exercise:
1. Codes vs. Labels¶
The current dataset has codes assigned for each value of a categorical variable. For instance, the variable gd_floor which indicates the type of ground floor has the following codes associated with it:
- 1, which denotes “Mud”
- 2, which denotes “Brick/Stone”
- 3, which denotes “Timber”
- 4, which denotes “RC”
- 5, which denotes “Other”
An alternate way of storing this information would be in the form of labels, as opposed to codes. That is,
- mud, which denotes “Mud”
- brick_stone, which denotes “Brick/Stone”
- timber, which denotes “Timber”
- rc, which denotes “RC”
- other, which denotes “Other”
Storing them as numbers require less space, but it comes at the cost of the user needing a reference for understanding what the number means.
It has been decided that values for all variables will stored in the form of codes. However, when this information is shown in the portal, they will be replaced with their respective labels. These labels will be extracted from a variable-label mapping table separately stored in the database.
2. Pre/Post Variables¶
A number of variables in the Household table seek to capture information about the difference in living conditions of the households, before and after the earthquake. These include:
- Residence (respreq, resposq)
- Source of Water (h2o_pre, h2o_pos)
- Source of cooking fuel (fir_pre, fir_pos)
- Source of light (lit_pre, lit_pos)
- Type of toilet (toilet_pre, toilet_pos)
- Type of fixed assets owned (ast_pre, ast_pos)
Given that there may be more than one HHD per building, Careful attention needs to be paid when aggregating this information at a building level in later stages
3. Multi select questions¶
Some of the questions, because of their multiselect nature has more than one column associated with them):
- Superstructure type has 11 columns ranging from sup_str1 to sup_str11
- Type of geotechnical risk has 7 columns ranging from gersk_ls1 to gersk_ls3
- Type of secondary use has 10 columns ranging from secuse_ls1 to secuse_ls10
In the case of multiselect columns, additional data cleaning work would be required to make information more usable.
4. Damage Assessment Variables:¶
Information for damage assessment is spread across groups of variables. For example, for users to get complete information on building foundation damage, they will have to go through three variables viz. dm_fndtn1, dm_fndtn2, dm_fndtn3. Other variables that have a similar nature include:
- dm_roof1, dm_roof2, dm_roof3
- corn_sep1, corn_sep2, corn_sep3
- diag_cr1, diag_cr2, diag_cr3
- pl_fail1, pl_fail2, pl_fail3
- op_fail1, op_fail2, op_fail3
- op_fl_nl1, op_fl_nl2, op_fl_nl3
- dm_gabl1, dm_gabl2, dm_gabl3
- delam1, delam2, delam3
- col_fail1, col_fail2, col_fail3
- beam_fl1, beam_fl2, beam_fl3
- str_case1, str_case2, str_case3
- parapet1, parapet2, parapet3
- clad_glz1, clad_glz2, clad_glz3
- clad_glz1, clad_glz2, clad_glz3
Furthermore, information for “No damage” is contained as a categorical value within the first out of three variable, as illustrated by the picure below.
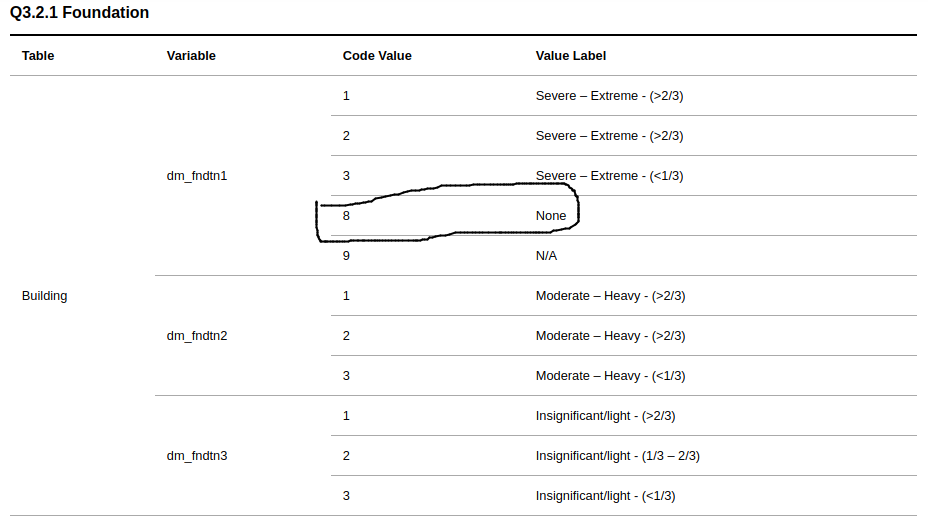
Variable names for damage assessment columns need to include severity related information, i.e. dm_fndtn_severe, dm_fndtn_moderate, dm_fndtn_insignfcant. In additions, information about ‘no damage should be captured in a separate variable.
5. Missing variable definitions¶
The data dictionary provided by CBS had left out definitions and range for the following 24 variables across the 8 tables. Fortunately, these definitions have been successfully extracted through variables labels available in theie respective SPSS(.sav) files.
Main table:
- rhouse_sa & rhouse_da: Number of residential house within same area and Number of residential house outside Enumeration Area
- ndam_c: No damage non-residential house number
- pdam_c: Partial damage non-residential house number
- cdam_c: Complete damage non-residential house number
Building table:
- delam1, delam2 and delam3: They represent damage assesment of delaminated structures
- fam_cn: Count of families in the building (or) Total family in the house
- hgt_pre & hgt_pos: Height of house in feet before and after earthquake
- pl_area: Plinth area in sq ft of house
- age: Age of house
- floor_pre & floor_pos: Number of floor before and after earthquake
Individual Table:
- age: Member’s age
Household Table:
- age: Age of household head
- hhd_size: Household size
- death_cn: Number of Death in the family within 12 months period
- loss_cn: Number of missing/handicapped/serious injured due to earthquake in the family
- edrop_cn: Number of students (level<=10) in the family who dropped school.
- pdrop_cn: Number of pregnent woman in the family who dropped regular checkup.
- vdrop_cn: Number of children who dropped vaccination due to earthquake.
- oc_ch_cn: Number of family member who changed/dropped occupation due to earthquake.
- respreqd: District code of usual residence of household head before earthquake
- resposqd: District code residence place of household after earthquake
House Other Place Table:
- haop_sn: Serial Number of House in other place
Death Table:
- age: Age of the dead person
Injured/Missing Table:
- age: Age of the person who is missing/injured
There are some common variable names that capture different information across different tables (like say, age and gender). To avoid confusion, all variable names need to be revisited to ensure they are more representative of the information that they hold